
Our goal with this post is to get you up and running with the OpenAI API as quickly as possible. We’re going to focus on a very basic technical implementation. If you’re interested in why you might want to integrate your custom Claris FileMaker solution with ChatGPT, check out this companion post by Cristos Lianides-Chin.
What is ChatGPT’s OpenAI API?
The integration of ChatGPT with Claris FileMaker happens through the OpenAI API, so let’s quickly explain what that is.
The OpenAI API is a connector that lets other systems, like apps and databases, talk directly to OpenAI’s powerful AI models, including ChatGPT.
Think of ChatGPT as the friendly, easy-to-use version for everyday people. It’s the chat interface that lets you have conversations and get instant answers.
But the OpenAI API is built for developers. It’s the powerful backbone that, while less user-friendly on its own, unlocks a world of possibilities. It lets you integrate AI into different systems, automate tasks, create summaries, interpret data, and so much more—all behind the scenes.
How to Set Up the ChatGPT OpenAI API with Claris FileMaker?
The OpenAI API documentation is a great place to start. From the main page, you can log in (or create a developer account). Once you have created your account, navigate to your account preferences, and on the Organization/Settings tab, enter an organization name, and note the Organization ID — you’ll need this later for your API request.
On the Billing tab, you’ll need to set up a payment method; each API request costs a few pennies, and you’ll get a block of free requests during your introductory period. Lastly, you’ll need to generate an API key in the User/API keys tab. Create a key and note it; you will need this for your API request.
Step 1: Testing the Demo and Basic Models
Launch the demo, and on the “prompts” layout, enter your Organization ID and API key in the setup area. Try one of the predefined prompts or create a new record and try your own. Enter a prompt (required), add some source text (optional), and try out the davinci or GPT-4 model.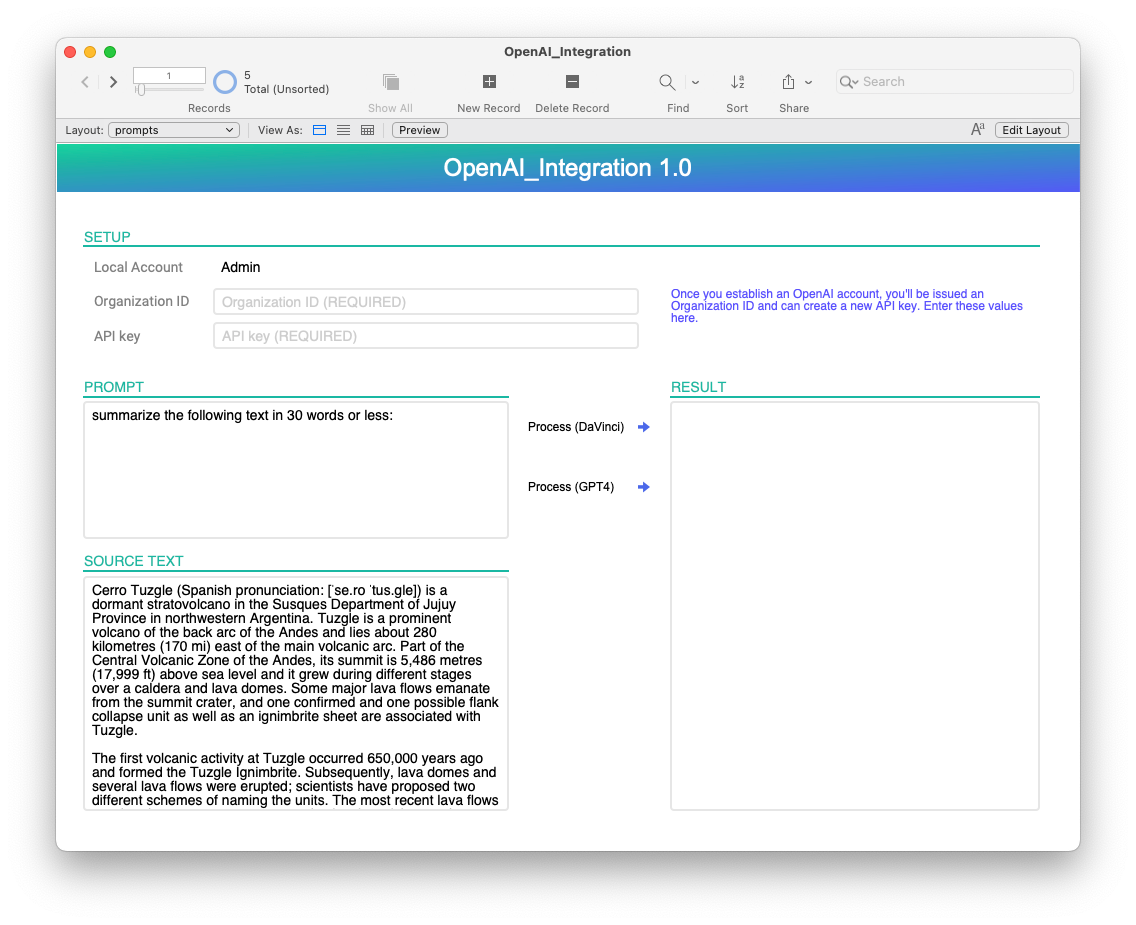
Step 2: Configuring the “Hello World” OpenAI API Script
As we dive behind the scenes and prepare to interact with the OpenAI API, let’s take a look at the “Hello World” script in the examples folder. This script runs a script from the private folder (“private.helloWorld”) and displays the response.
This “private” script assembles the API request and calls the script “private.APIRequest”, and returns the response which we display in a custom dialog. If we simply run the “Hello World” script, we should get a simple custom dialog that displays “Hello World!”, and in this case, it’s the large language model davinci-003 that generates this text for us.
To work this magic, we’ve referenced the Completions endpoint documentation and configured an appropriate POST request. According to the documentation, we need to specify which model to use, and we need a prompt.
The model is the large language model that we want to use — note that there are lots of different models to explore, and not all endpoints support all models. The prompt is our question or statement that we want the model to evaluate. In this case, our prompt (say “Hello World”) is pretty simple!
The script “private.helloWorld” assembles the relevant data for the request, executes the request using the Insert from URL script step (see the subscript “private.APIRequest”), and returns the result:
If all goes well, we’ll get a response from the API that looks something like this:{"choices" : [{"finish_reason" : "stop","index" : 0,"logprobs" : null,"text" : "\n\nHello World!"}],"created" : 1688909468,"id" : "cmpl-7aOnE0GYjfFrPkkY9pqTbf4atMN3U","model" : "text-davinci-003","object" : "text_completion","usage" : {"completion_tokens" : 5,"prompt_tokens" : 5,"total_tokens" : 10}}
There’s a lot in here to unpack, but the value we’re looking for is in the first (and only) object in the “choices” array, specifically the value for “text”. Of note, the usage object will let us know how many tokens we’ve used for this request. Armed with this JSON result, the “Hello World” example script unpacks the text result and displays “Hello World!” in a custom dialog.
Step 3: Authenticating the ChatGPT OpenAI API
When integrating with any API, authentication is usually the first hurdle, and the OpenAI API is no exception. In this case, we’re going to pass the Organization ID and secret key as headers in each request. Our request will need to take the form: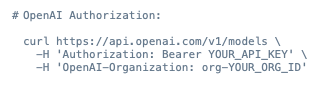
To accomplish this, we’ll set up our cURL options in a variable and pass this as part of our request via the “Insert from URL” script step. See step 17 in the script above and the details of that script step here: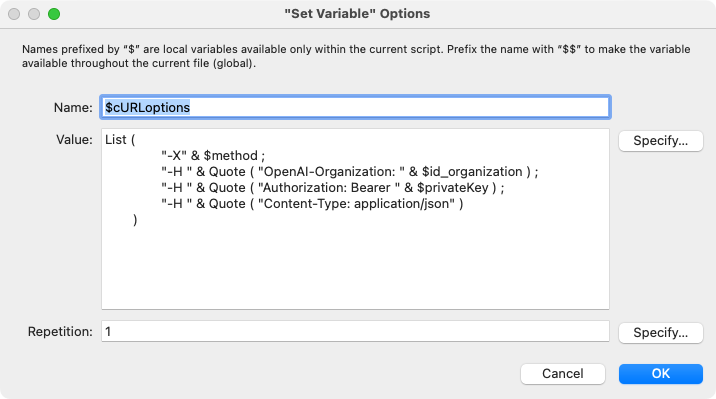
Note: The Quote() and List() functions provide a convenient way to handle the embedded quote characters and format the output for readability when debugging.
Step 4: How to Choose the Best Model for Your FileMaker Integration?
As noted above, not all endpoints support all models so depending on what you want to accomplish, you may have a limited set of models to choose from. Models have different capabilities and significantly different fees and it’s important to choose carefully. You’ll want to experiment with the different models to ensure you’re getting the best possible response from your prompts.
You’ll be charged a fee based on how many tokens you use, and different models have different rates, but all models use this token-based fee structure. Essentially, longer prompts and longer responses will use more tokens, and your fees will be higher. At this time, pricing ranges from $0.0015 to $0.12 per 1,000 tokens depending on the model you choose.
Example of Using the “text-davinci-003” OpenAI API Model
With the Hello World example under our belt, now we can send a more interesting prompt to the API. Let’s use the text-davinci-003 model (the same one we used for the Hello World example) to take a user prompt and return a text completion. The mechanics are virtually the same as before; we just need to assemble the prompt based on user input
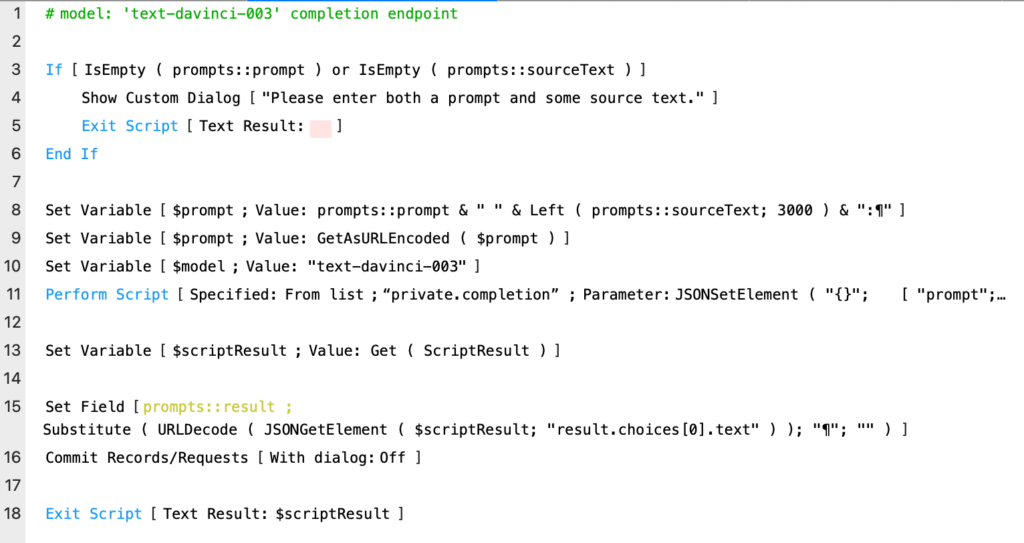
In line 8, we’re ensuring that we only send 3000 characters from our sourceText field — this is just a crude way to limit the amount of data we’re sending to the API (minimizing our token usage). Of more importance is line 9 where we are URL encoding the prompt to ensure we don’t submit a malformed request.
The rest is nearly identical to the Hello World example: we assemble our request, send it to the API (see the scripts “private.completion”, and “private.APIRequest” for more details), and process the response.
What are the Main Practical Applications of the OpenAI API for Businesses?
The OpenAI API lets your company integrate its systems and apps, like FileMaker, with OpenAI’s powerful AI models, including ChatGPT. This opens the door to creating amazing automations for your internal business processes.
One of the most useful applications is the automatic generation of reports and summaries. Instead of manually sifting through raw data, the API can take that data and turn it into a clear, concise text that’s ready for you to read or present.
When the OpenAI API is integrated with FileMaker, it can also power smart dashboards. These dashboards make it easier to find key insights and use AI to guide your decision-making.
The integration also allows you to build customer service bots. These bots can effectively chat with users, provide automatic and personalized responses, or even hand the conversation off to the right team member.
How Much Does It Cost to Use the ChatGPT API?
OpenAI API costs are based on token consumption. Think of tokens as the units that represent chunks of text, essentially small groups of words.
Every request you make uses both input and output tokens. Input tokens are the words in your prompt, while output tokens are the words used in the API’s response. The billing for these is separate.
The price varies depending on the model you choose:
- GPT-3.5 Turbo: about $0.50 per million input tokens + $1.50 per million output tokens;
- GPT-4: approximately $30 per million input tokens + $60 per million output tokens;
- Newer models may have higher costs (e.g., GPT-4.5: $75 per million input + $150 per million output).
This pricing model highlights a crucial point for any strategy: finding the balance between token usage and productivity gains. In other words, your automation processes need to be implemented as efficiently as possible.
This means you should:
- Optimize your prompts to avoid excessive token consumption;
- Set token limits on responses to prevent the API from generating overly long text;
- Choose the right model for the job. Don’t use GPT-4 or GPT-5 if GPT-3.5 can handle the task just as well;
- Use tags and monitoring tools to track token usage by team, helping you find ways to improve efficiency over time.
Summary
This demo file and examples are designed to simply get you started. Where this journey takes us is still very much an unanswered question. At Codence, we’re looking into all sorts of ways to leverage this technology to enhance the solutions that we build for our customers (and for ourselves). Summarizing long email threads, writing code, predicting outcomes, writing documentation, and assisting users are all areas that we are exploring.
How are you using this technology? We’d love to know!
Read more

Built with you in mind
Speak to one of our expert consultants about making sense of your data today. During
this free consultation, we'll address your questions, learn more about your business, and
make some immediate recommendations.